The power of pixels: Modelling with images
![]()
This post provides the notes for the plenary I gave for the Auckland Mathematical Association (AMA) about using images as a source of data for teaching statistical investigations.
You might be disappointed to find out that my talk (and this post) is not about the movie pixels, as my husband initially thought it was. It’s probably a good thing I decided to focus on pixels in terms of data about a computer or digital image, as the box office data about pixels the movie suggests that the movie didn’t perform so well 🙂 Instead for this talk I presented some examples of using images as part of statistical investigations that (hopefully) demonstrated how the different combinations of humans, digital technologies, and modelling can lead to some pretty interesting data. The abstract for the talk is below:
How are photos of cats different from photos of dogs? How could someone determine where you come from based on how you draw a circle? How could the human job of counting cars at an intersection be cheaply replaced by technology? I will share some examples of simple models that I and others have developed to answer these kinds of questions through statistical investigations involving the analysis of both static and dynamic images. We will also discuss how the process of creating these models utilises statistical, mathematical and computational thinking.
As I was using a photo of my cat Elliot to explain the different ways we can use images to collect data, a really funny thing happened (see the embedded tweet below).
When @annafergussonnz is talking about a cat image in her plenary talk “Power of Pixels” #thatisarealcat #mtbos #mathchat pic.twitter.com/WsHoTNCG3Y
— Subash Chandar K (@elsubash) September 1, 2017
Yes, an actual real #statscat appeared in the room! What are the chances of that? 🙂
Pixels are the squares of colour that make up computer or digital (raster) images. Each image has a certain number of pixels e.g. an image that is 41 pixels in width and 15 pixels in height contains 615 pixels, which is an obvious link to concepts of area. The 615 pixels are stored in an ordered list, so the computer knows how to display them, and each pixel contains information about colour. Using RGB colour values (other systems exist), each pixel contains information about the amounts of red, green and blue on a scale of 0 to 255 inclusive. To get at the information about the pixels is going to require some knowledge of digital technologies, and so the use of images within statistical investigations can be a nice way to teach objectives from across the different curriculum learning areas.
Using images as a source of data can happen on at least three levels. Using the aforementioned photo of my cat Elliot, humans could extract data from the image by focusing on things they can see, for example, that that image is a black and white photo and not in colour, that there are two cats in the photo, and that Elliot does not appear to be smiling. Data that is also available about the image using digital tech includes variables such as the number of pixels, the file type and the file size. Data that can be generated using models related to this image could be identifying the most prominent shade of grey, the likelihood this photo will get more than 100 likes on instagram and what the photo is of (cat vs dog for example, a popular machine learning task).

Static images
The first example used the data, in particular the photos, collected as part of the ongoing data collection project I have running about cats and dogs (the current set of pet data cards can be downloaded here). As humans, we can look at images, notice things that are different and these features can be used to create variables. For example, if you look at some of the photos submitted: some pets are outside while others are inside; some pets are looking at the camera while others are looking away from the camera; and some are “close ups” while others taken from a distance.

These potential variables are all initially categorical, but by using digital technologies, numerical variables are also possible. To create a measure of whether a photo is a “close up” shot of a pet, the area the pet takes up of the photo can be measured. This is where pixels are super helpful. I used paint.net, free image editing software, to show that if I trace around the dog in this photo using the lasso tool that the dog makes up about 61 000 pixels. If you compare this figure to the total number of pixels in the image (90 000), you can calculate the percentage the dog makes up of the photo.

For the current set of pet data card, each photo now has this percentage displayed. Based on this very small sample of six pets, it kind of looks like maybe cats typically make up a larger percentage of the photo than dogs, but I will leave this up to you to investigate using appropriate statistical modelling 🙂

For a pretty cool example of using static images, humans, digital technologies and models, you should take a look at how-old.net. As humans, we can look at photos of people and estimate their age and compare our estimates to people’s actual ages. What how-old.net has done is used machine learning to train a model to predict someone’s age based on the features of the photo submitted. I asked teachers at the talk to select which of the three photos they thought I looked the youngest in (most said B), which is the same photo that the how-old.net model predicted I looked the youngest in. A good teaching point about the model used by how-old.net is that it does get updated, as new data is used to refine its predictions.

You can also demonstrate how models can be evaluated by comparing what the model predicts to the actual value (if known). Fortunately I have a large number of siblings and so a handy (and frequently used) range of different aged people to test the how-old.net model. Students could use public figures, such as athletes, politicians, media personalities or celebrities, to compare each person’s actual age to what the model predicts (since it’s likely that both photos and ages are available on the internet).

There is also the possibility of setting up an activity around comparing humans vs models – for the same set of photos, are humans better at predicting ages than how-old.net? Students could be asked to consider how they could set up this kind of activity, what photos could they use, and how would they decided who was better – humans or models?
Drawings
The next example used the set of drawings Google has made available from their Quick! Draw! game and artificial intelligence experiment. I’ve already written a post about this data set, so have a read of that post if you haven’t already 🙂 In this talk, I asked teachers to draw a quick sketch of cat and then asked them to tell me whether they drew just the face, or the body as well (most drew the face and body – I’m not sure if the appearance of an actual cat during the talk influenced this at all!) I also asked them to think about how many times they lifted their pen off the paper. I probably forgot to say this at the time, but for some things humans are pretty good at providing data but for others, digital technologies are better. In the case of drawing and thinking about how many strokes you made while drawing, we would get more accurate data if we could measure this using a mouse, stylus or touchscreen than asking people to remember.

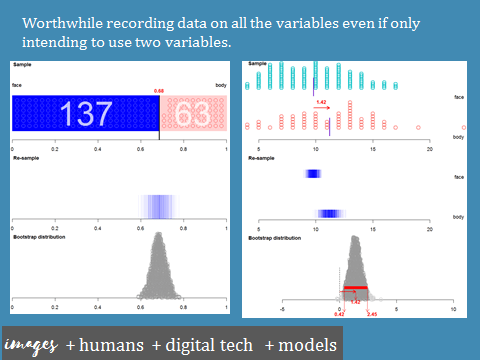
Using the random sampler tool that I have set up that allows you to choose one of the objects players have been asked to draw for Quick! Draw!, I generated a random sample of 200 of the drawings made when asked to draw a cat. The data the can be used from each drawing is a combination of what humans and digital technologies can measure. The drawing itself (similar to the photos of pets in the first example) can be used to create different variables, for example whether the sketch is of the face only, or the face and body. Other variables are also provided, such as the timestamp and country code, both examples of data that is captured from players of the game without them necessarily realising (e.g. digital traces).

After manually reviewing all 200 drawings and recording data about the variables, I used iNZight VIT to construct bootstrap confidence intervals for the proportion of all drawings made of cats in the Quick! Draw! dataset that were only of faces and for the difference between the mean number of strokes made for drawings of cats in the Quick! Draw! dataset that were of bodies and mean number of strokes made for drawings of cats in the Quick! Draw! dataset that were of faces. Interestingly, while the teachers at the talk mostly drew sketches of cats with bodies, most players of Quick! Draw! only sketch the faces of cats. This could be due to the 20 second time limit enforced when playing the game. It makes sense that the, on average, Quick! Draw! players use more strokes to draw cats with bodies versus cats with just faces. I wished at the time that I had also recorded information about the other variables provided for each drawing, as it would have been good to further explore how the drawings compare in terms of whether the game correctly identified more of the face-only drawings of cats than the body drawings.
What is also really interesting is the artificial intelligence aspect of the game. The video below explains this pretty well, but basically the model that is used to guess what object is being drawn is trained on what previous players of the game have drawn.
From a maths teachers perspective, this is a good example of what can go wrong with technology and modelling. For example, players are asked to draw a square, and because the model is trained on how they draw the object, players who draw four lines that are roughly perpendicular behave similarly from the machine’s perspective because the technology is looking for commonalities between the drawings. What the technology is not detecting is that some players do not know what a square is, or think squares and rectangles are the same thing. So the data being used to train the model is biased. The consequence of this bias is that the model will now reinforce players misunderstanding that a rectangle is a square by “correctly” predicting they are drawing a square when they draw a rectangle! An interesting investigation I haven’t done yet would be to estimate what percentage of drawings made for squares are rectangles 🙂 I would also suggest checking out some of the other “shape” objects to see other examples e.g. octagons.

Using a more complex form of the Google Quick! Draw! dataset, Thu-Huong Ha and Nikhil Sonnad analysed over 100 000 of the drawings made of circles to show how language and culture influences sketches. For example, they found that 86% of the circles drawn by players in the US were drawn counter clockwise, while 80% of the circles drawn by players in Japan were drawn clockwise. To me, this is really fascinating stuff, and really cool examples of how using images as a source of data can result in really meaningful investigations about the world.
Animation
The last example I used was about using videos as a source of data for probability distribution modelling activities. I’ve presented some workshops before where I used a video (traffic.mp4) from a live streaming traffic camera positioned above a section of the motorway in Wellington. Focusing on the lane of traffic closest to the front of the screen, I got teachers to count how many cars arrived to a fixed point in that lane every five seconds. This gave us a nice set of data which we could then use to test the suitability of a Poisson distribution as a model.

For this talk, I wanted to demonstrate how humans could be replaced (potentially) by digital technologies and models. Since the video is a collection of images shown quickly (around 50 frames per second), we can use pixels, or potentially just a single pixel, in the images to measure various attributes of the cars. About a year ago, I set myself the challenge of exploring whether it would be possible to glean information about car counts, car colours etc. and shared my progress with this personal project at the end of the talk.

So, yes there does exist pretty fancy video analysis software out there that I could use to extract the data I want, but I wanted to investigate whether I could use a combination of statistical, mathematical and computational thinking to create my own model to generate the data. As part of my PhD, I’m interesting in finding out what activities could help introduce students to the modern art and science of learning from data, and what is nice about this example is that idea of how the model could count how many cars are arriving every five seconds to a fixed point on the motorway is actually pretty simple and so potentially a good entry point for students.
The basic idea behind the model is that when there are no cars at the point on the motorway, the pixel I am tracking is a certain colour. This colour becomes my reference colour for the model. Using the RBG colour system, for each frame/image in the traffic video, I can compare the current colour of the pixel e.g. rgb(100, 250, 141) to the reference colour e.g. rgb(162, 158, 162). As soon as the colour changes from the reference colour, I can infer this means a car has arrived to the point on the motorway. And as soon as the colour changes back to the reference colour, I can infer that the car has left the point on the motorway. While the car is moving past the point, I can also collect data on the colour of the pixel from each frame, and use this to determine the colour of the car.
I’m still working on the model (in that I haven’t actually modified it since I first played around with the idea last year) and the video below shows where my project within CODAP (Common Online Data Analysis Platform) is currently at. When I get some time, I will share the link to this CODAP data interactive so you and your students can play around with choosing different pixels to track and changing other parameters of the model I’ve developed 🙂
You might notice by watching this video that the model needs some work. The colours being recorded for each car are not always that good (average colour is an interesting concept in itself, and I’ve learned a lot more about how to work with colour since I developed the model) and some cars end up being recorded twice or not at all. But now that I’ve developed an initial model to count the cars that arrive every five seconds, I can compare the data generated from the model to the data generated by humans to see how well my model performed.

You can see at the moment, that the data looks very different when comparing what the humans counted and what the digital tech + model counted. So maybe the job of traffic counter (my job during university!) is still safe – for now 🙂
Going crackers
I didn’t get time in the talk to show an example of a statistical investigation that used images (photos of animal crackers or biscuits) to create a informal prediction model. I’ll write about this in another post soon – watch this space!
