
Using data and simulation to teach probability modelling

This post provides the notes and resources for a workshop I ran for the Auckland Mathematical Association (AMA) on using data and simulation to teach probability modelling (specifically AS91585/AS91586). This post also includes notes about a workshop I ran for the AMA Statistics Teachers’ Day 2016 about my research into this area.
Using data in different ways
The workshop began by looking at three different questions from the AS91585 2015 paper. What was similar about all three questions was that they involved data, however, how this data was used with a probability model was different for each question.
For the first question (A), we have data on a particular shipment of cars: we know the proportion of cars with petrol cap on left-hand side of the car and the percentage of cars that are silver. We are then told that one of the cars is selected at random, which means that we do not need to go beyond this data to solve the problem. In this situation, the “truth” is the same as the “model”. Therefore, we are finding the probability.
For the second question (B), we have data on 10 cars getting petrol: we know the proportion of cars with petrol caps on the left-hand side of the car. However, we are asked to go beyond this data and generalise about all cars in NZ, in terms of their likelihood of having petrol caps on the left-hand side of the cars. This requires developing a model for the situation. In this situation, the “truth” is not necessarily the same as the “model”, and we need to take into account the nature of the data (amount and representativeness) and consider assumptions for the model (the conditions, the model applies IF…..). Therefore, when we use this model we are finding an estimate for the probability.
For the third question (C), we have data on 20 cars being sold: we know the proportion of cars that have 0 for the last digit of the odometer reading (six). What we don’t know is if observing six cars with odometer readings that end in 0 is unusual (and possibly indicative of something dodgy). This requires developing a model to test the observed data (proportion), basing this model on an assumption that the last digit of an odometer reading should just be explained by chance alone (equally likely for each digit). Therefore, when we use this model, we generate data from the model (through simulation) and use this simulated data to estimate the chance of observing 6 (or more) cars out of 20 with odometer readings that end in 0. If this “tail proportion” is small (less than 5%), we conclude that chance was not acting alone.
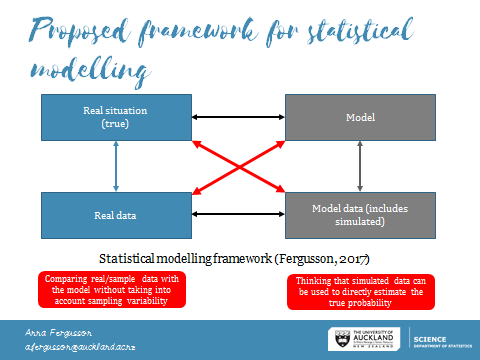
There’s a lot of ideas to get your head around! Sitting in there are ideas around what probability models are and what simulations are (see the slides for more about this) and as I discovered during my research last year with teachers and probability distribution modelling, these ideas may need a little more care when defining and using with students. The main reason I think we need to be careful using data when teaching probability modelling is because it matters whether you are using data from a real situation, where you do not know the true probability, or whether you are using data that you have generated from a model through simulation. Each type of data tells you something different and are used in different ways in the modelling process. In my research, this led to the development of the statistical modelling framework shown below:
All models are wrong but some are more wrong than others: Informally testing the fit of a probability distribution model
At the end of 2016, I presented a workshop at the AMA Statistics Teachers’ Day based on my research into probability distribution modelling (AS91586). This 2016 workshop also went into more detail about the framework for statistical modelling I’m developing. The video for this workshop is available here on Census At School NZ.
We have a clear learning progression for how “to make a call” when making comparisons, but how do we make a call about whether a probability distribution model is a good model? As we place a greater emphasis on the use of real data in our statistical investigations, we need to build on sampling variation ideas and use these within our teaching of probability in ways that allow for key concepts to be linked but not confused. Last year I undertook research into teachers’ knowledge of probability distribution modelling. At this workshop, I shared what I learned from this research, and also shared a new free online tool and activities I developed that allows students to informally test the fit of probability distribution models.
During the workshop, I showed a live traffic camera from Wellington (http://wixcam.citylink.co.nz/nph-webcam.cgi/terrace-north), which was the context for a question developed and used (the starter question AKA counting cars). Before the workshop, I recorded five minutes of the traffic and then set up a special html file that pauses the video every five seconds. This was so teachers at the workshop (and students) could count the number of cars passing different points on the motorway (marked with different coloured lines) every five seconds. To use this html file, you need to download both of these files into the same folder – traffic.html and traffic.mp4. I’ve only tested my files using the Chrome browser 🙂
If you don’t want to count the cars yourself, you can head straight to the modelling tool I developed as part of my research: http://learning.statistics-is-awesome.org/modelling-tool/. In the dropdown box under “The situation” there are options for the different coloured points/lines on the motorway. The idea behind getting teachers and students to actually count the cars was to try to develop a greater awareness of the complexity of the situation being modelled, to reinforce the idea that “all models are wrong” – that they are approximations of reality but not the truth. Also, I wanted to encourage some deeper thinking about limitations of models. For example, in this situation, looking at five second periods, there is an upper limit on how many cars you can count due to speed restrictions and following distances. We also need to get students to think more about model in terms of sample space (the set of possible outcomes) and the shape of the distribution (which is linked to the probabilities of each of these outcomes), not just the conditions for applying the probability distribution 🙂
In terms of the modelling tool, I developed a set of teaching notes early last year, which you can access in the Google drive below. This includes some videos I made demonstrating the tool in action 🙂 I also started developing a virtual world (stickland http://learning.statistics-is-awesome.org/stickland-modelling/) but this is still a work in progress. Once you have collected data on either the birds or the stick people, you can copy and paste it into the modelling tool. There will be more variables to collect data on in the future for a wider range of possible probability distributions (including situations where none is applicable).
Slides from IASC-ARS/NZSA 2017 talk
Resources for workshop (via Google Drive)