
Making awesome connections between standards …


Is there a way to get some great connections happening between standards that could also benefit student learning? Could we use the same set of sample data to explore relationships between different combinations of categorical and numerical variables and as a consequence get deeper statistical and contextual understanding happening? To do this requires an overall question that sits above the individual investigative questions required for each standard. For this example, the overall question is about budget brands – are they just like the real thing? |

An important note regarding using an approach like this for assessment is that both the standards for AS91581 and AS91582 require the use of a multivariate data set. The intention is that students are supplied with this data set (it is not a requirement that students collect data themselves) and that the data set has enough different variables (both numerical and categorical) so that students have a choice of which variables to use for their investigations for each standard. So if you just used the data set I have created for this example it would not be sufficient for assessment against these standards as there are only three variables (brand, width, length). So, what could you do? I see no reason why you could not involve your students in the creation of the multivariate data set and then give them this data set back for use in their learning/assessment. For this context, you would also record/measure colour, weight and volume using appropriate equipment. Note that our overall question has become a little more specific by adding on “Can you tell them apart based on length and width?” |

Throughout the measuring and recording process, I was actually not sure what I was going to find when I looked at the data. By the time I had finally finished measuring all the jelly beans and could chuck the data into iNZight to see what was going on I was fully invested in whether the data would reveal anything – I’m not sure this would have been the case if I had just been given the data (but I will give you the data at the bottom of this page!) These features are interesting because they are not necessarily ones I could detect with my eye but they do make sense in terms of manufacturing and quality control systems and processes – I really like for this context how variation is an important feature of the data to discuss. Now might be a good time to watch a video about how jelly beans are made 🙂 |
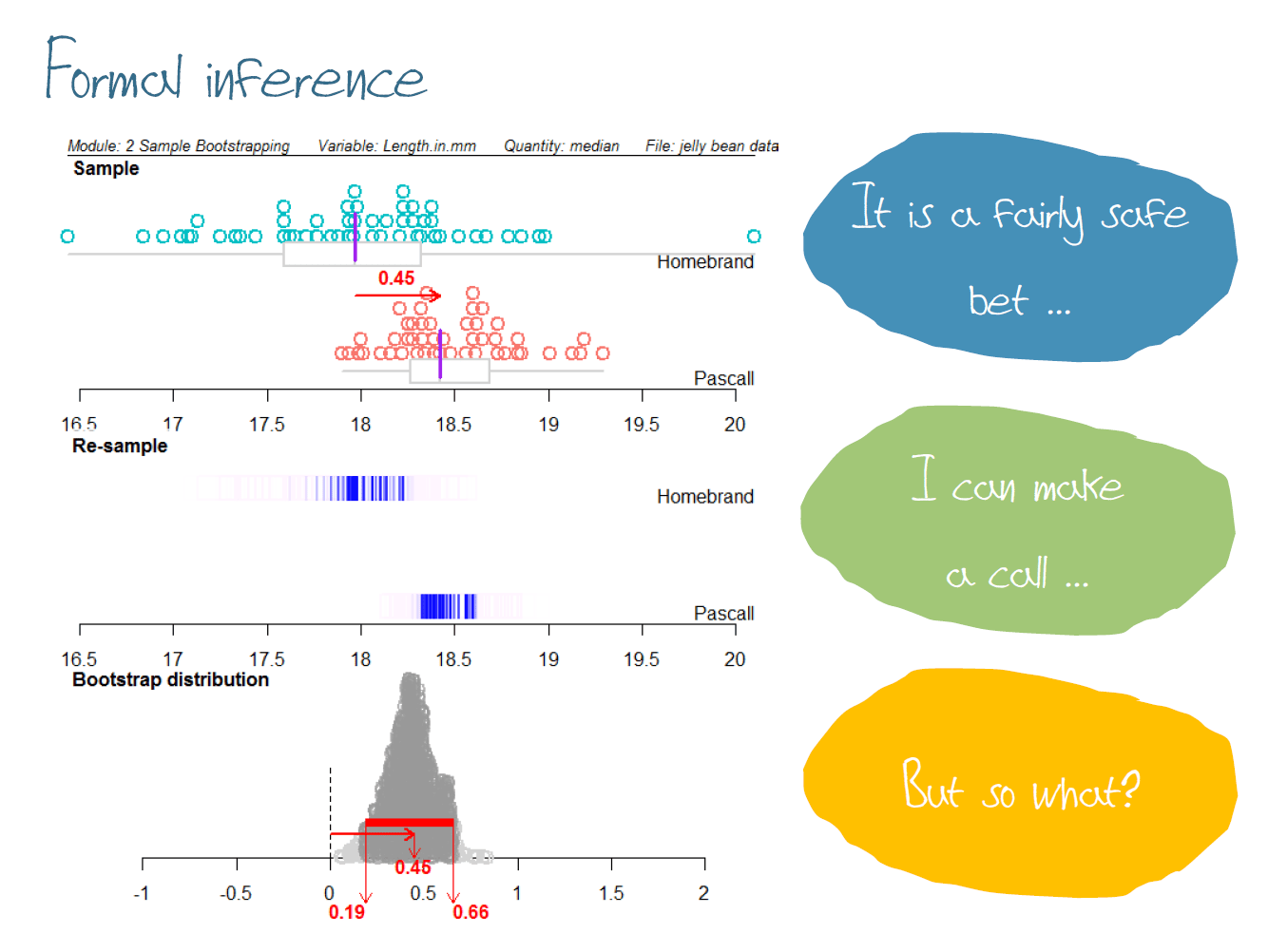
The actual formal inference for this example – answering an investigative question like “Is there a difference between the median length of Pascall jelly beans and the median length of Homebrand jelly beans?” – is only interesting because of the “So what?” consideration, which leads us back to the overall questions “Budget brands – are they just like the real thing? Can you tell them apart based on length and width?”. Somehow I went through all my 12 years of classroom teaching without ever using calipers to take measurements but for this context (manufacturing) using a tool that can measure more accurately than a standard ruler is important. A question that came from the audience during the plenary was about researching context and whether I knew if the jelly beans were made by the same factory, since this teacher knew that for some products (like in the video above) those that are not good enough to go in the “branded” packages and used in the “budget” brands. These two types of jelly beans are both made in Australia but by different factories but this could be information further explored by students to make stronger connections to the context. |
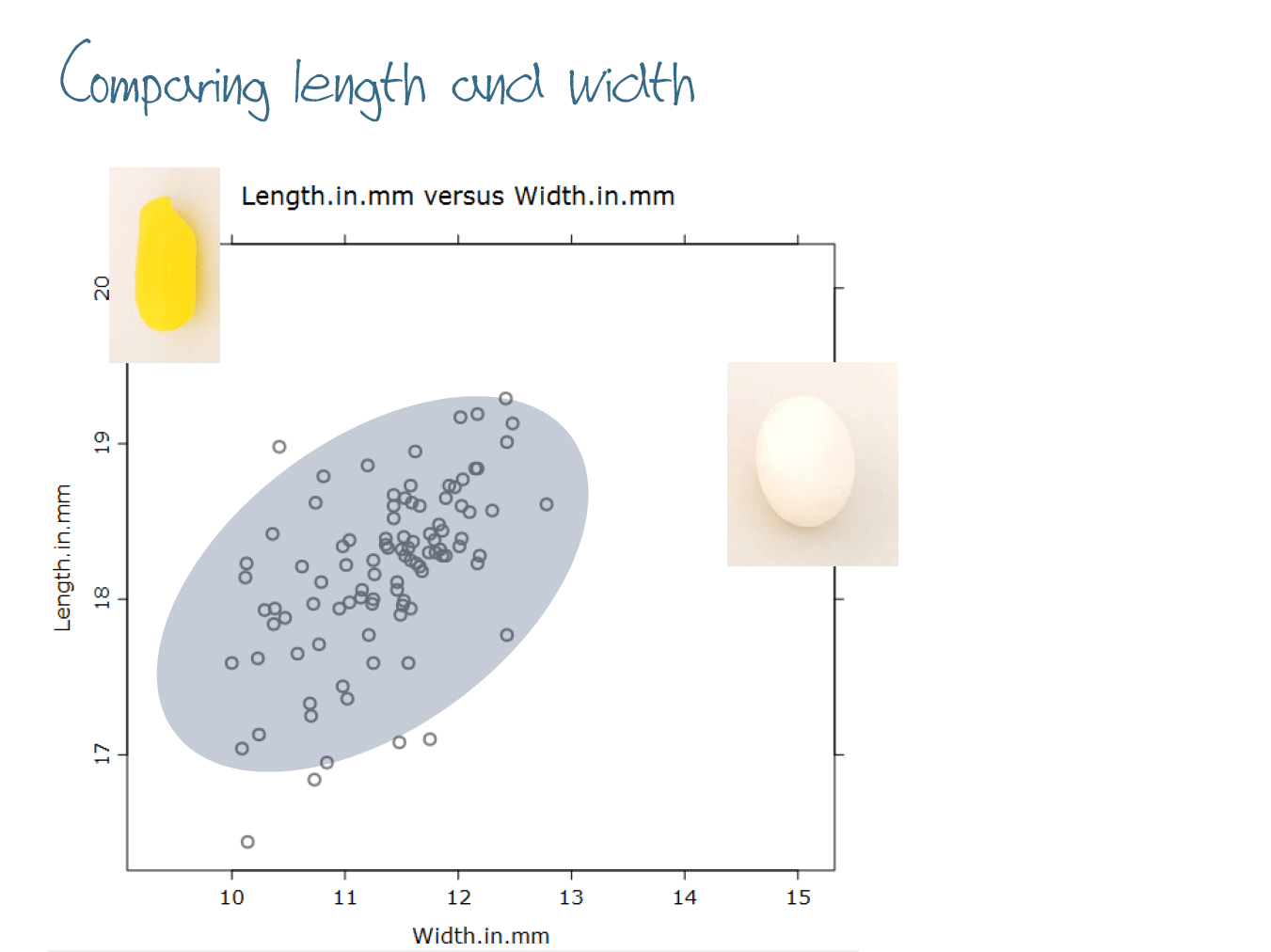
Since jelly beans are supposed to look like beans we would expect there to be a relationship between the length and width – and the resulting scatter plot kind of looks like a jelly bean too 🙂 There are two pairs of values that stand out which do represent actual jelly beans (as shown in the picture above). Generally we can see a tendency for wider jelly beans to be longer, but there is a reasonable amount of scatter. Why do we have this scatter? The sources of variation again can be partly explained by how the jelly beans are made (as shown in the video) but also by higher or lower levels of quality control which leads nicely to…… |

…. adding a third variable (Brand) to the plot using colour. What I really like about this particular set of data is that when we subset on Brand we are doing this for a reason aligned to our overall question about budget brands being just like the real thing, not just as a “tick box” approach or as a procedure. Decisions we make about exploring data using different techniques and approaches should have a good basis and be motivated to find something out that is related to the overall question(s) being investigated. |

Lastly, I think this analysis is a great formative assessment question to give students regarding discussing the influence of possible outliers on the model(s) they have fitted. Why would we not expect the model to change much for the Homebrand jelly beans but we would for the Pascall jelly beans? We want students to have the statistical knowledge to be able to answer this based on what they see above, not just try the model with and without the outlier as a procedure (although doing this can help with building conceptual understanding). At a minimum, I would want students to discuss that for the Homebrand jelly beans the relationship is weak (large amount of scatter) so sure if you removed the outlier the correlation coefficient would increase, but your predictions are not going to be that precise anyway, so the line (slope and/or intercept for the model) moving slightly when you exclude the outlier won’t make your predictions “better”. |
Jelly bean sample data as a CSV file: jelly bean data
This post is based on a plenary I did for the Christchurch Mathematical Association (CMA) Statistics Day in November 2015 where I presented 10 ways to embrace the awesomeness that is our statistics curriculum. You can find all the posts related to this plenary in one place here as they are written.