
What do we know about witches?
This what the question that I posed to my ArtsGen students (see this post for more about these students) at the start of this lesson. But I think we need some back story first.
Why witches? Usually I’m all about using real data when teaching statistics, however, in this case I made an exception. Firstly, I was trying to engage non-statistics students and the more intrigue I could bring into the lesson the better I thought my chances were. Secondly, these students had completed a history topic earlier in the semester on the Salem witch trials and I wanted to capitalise off this to draw them in. So I made up a data set of 120 women (60 witches and 60 non-witches) and compiled these into data cards.

Before this lecture I gave the students this article to read. The article describes how Target knew that a teenage customer was pregnant based on data about her shopping habits that had been collected and analysed. I showed the students how a basic classification model could be used to identify a possibly pregnant customer.
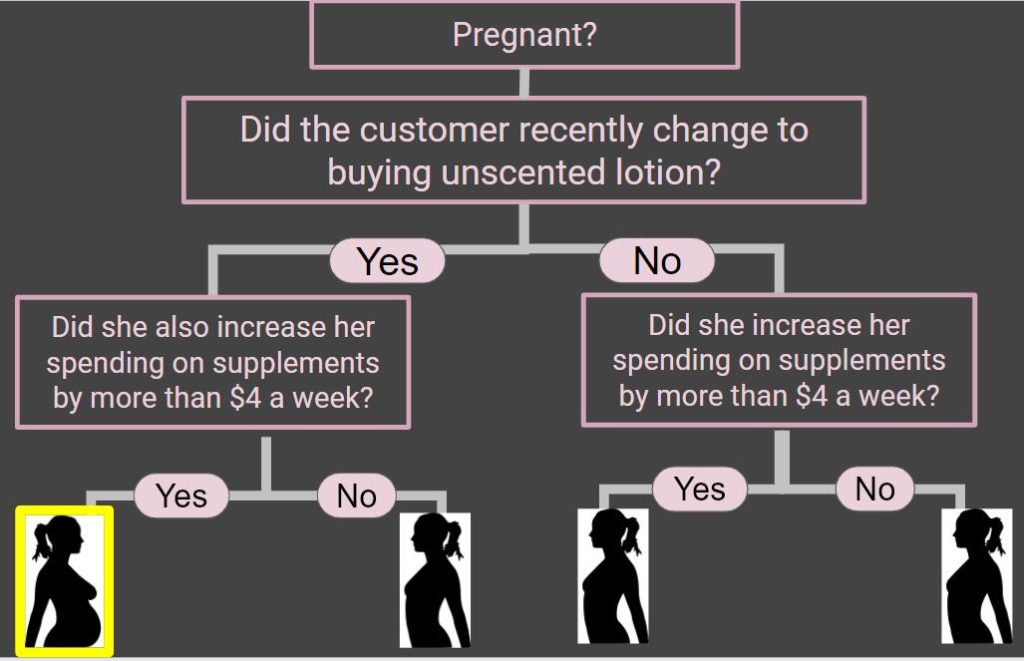
The aim of the following in-class activity was to use a similar technique to try and identify witches.
So, what do we know about witches? Or, more specifically, how are witches different from non-witches? We brainstormed and the students came up with some ideas, and I included some of my own (such as, based on the sketch from Monty Python and the Holy Grail, that a witch weighs the same as a duck).
Then we explored the data in iNZight Lite to see if any of the traits we expected showed up in the data.
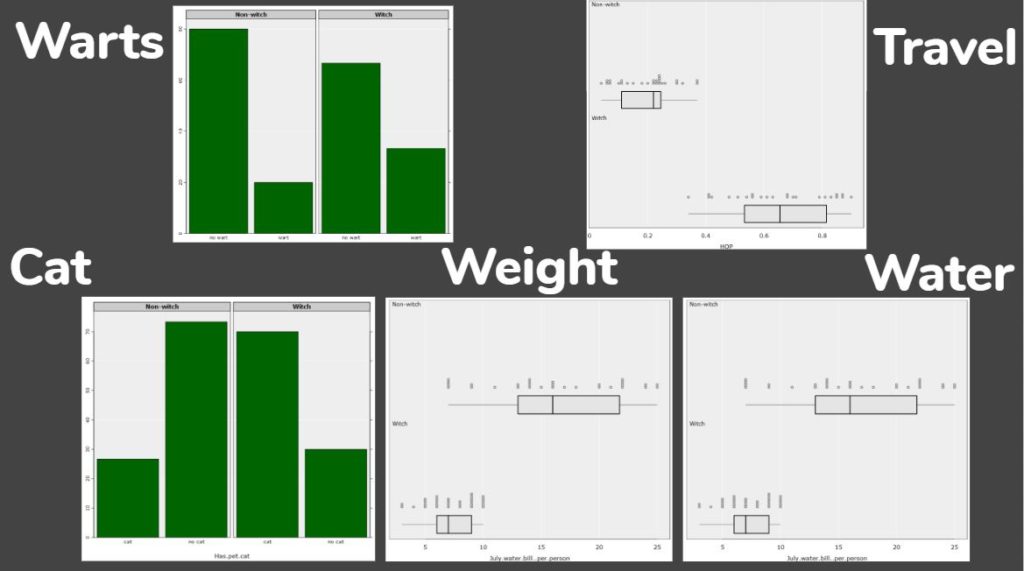
Students (working in pairs) were then given a set of 20 data cards (10 witches and 10 non-witches) and instructed to develop a classification tree to separate the witches from the non-witches. They started with one rule and then moved on to using two rules. At the end they wrote down the successful classification rates.
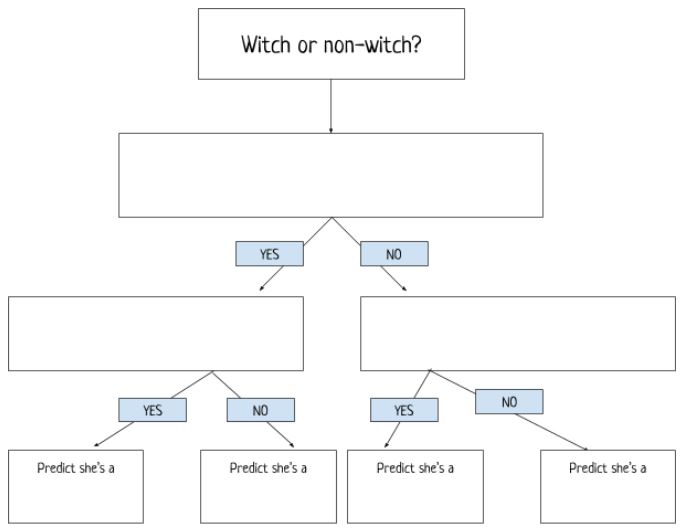
Once the students had their rules I asked the pairs to swap data cards and to run the new cards through the classification tree. They re-calculated the success rates and almost all pairs noticed that their model was less successful with the new data cards. This gave me a chance to discuss training and testing data with the students and to share this YouTube clip:
My final message to students was that with great power comes great responsibility and that these models, and ones like them, are used by data scientists all the time with real world implications.

For our model we needed to be careful, what if we misclassified someone as a witch? What if we correctly classified someone as a witch, but they’re a good witch? Thinking back to the example from Target, what are the real world implications with using data from shoppers to target advertising? The students were left with lots to think about!

Emma is a Professional Teaching Fellow in the Department of Statistics, University of Auckland.