
When I first started developing interactives to use in large intro stats lectures, I didn’t really have a clear idea of what would work well in terms of the design beyond: (1) students do stuff on their devices; (2) the stuff they do generates data; and (3) we use that data to learn things. I started with apps that did one thing (e.g. collecting data on students tapping their phones, stashing this in a Google sheet) and then moved to longer extended interactives like the one this post is about. I thought it would be good to revisit this old interactive (developed in 2017), and share my thoughts for what are features to keep, change or introduce, when I get time to re-design it!
My bootstrapping with stick people interactive
This interactive uses the same data-context and learning goal as Emma described in her Bootstrapping with Lego post – the weights of a sample of nine first stage males are used to introduce students to bootstrapping. My interactive was designed to be completed after the activity Emma describes (sans Lego), as a revision activity. The interactive was designed to work for dual purposes: (1) to be carried out with students in a large lecture; (2) to be used outside of a lecture as “dynamic revision notes”.
Before we start the activity, I instruct the students not to click the buttons in the interactive until I tell them to, so we can move through the interactive together. After directing students to the interactive, I ask them to select nine stick people/males from the population of over 500 first stage male students at the University. The stick people move around the screen and have been randomly positioned when the interactive loads.
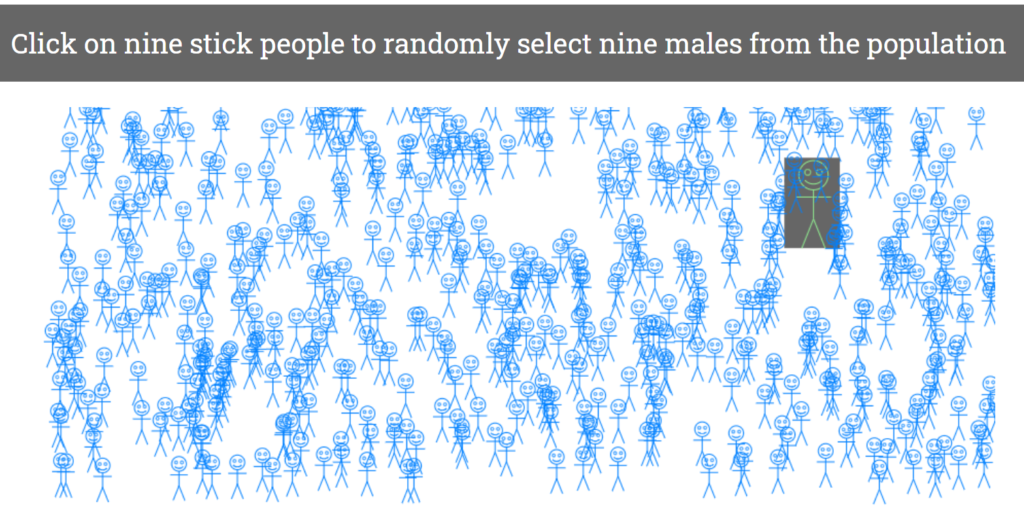
This gives each student in the lecture their own random sample of nine males. The interactive then displays the weights of the nine males they have selected, along with their weights, and the median weight of the males in their sample.
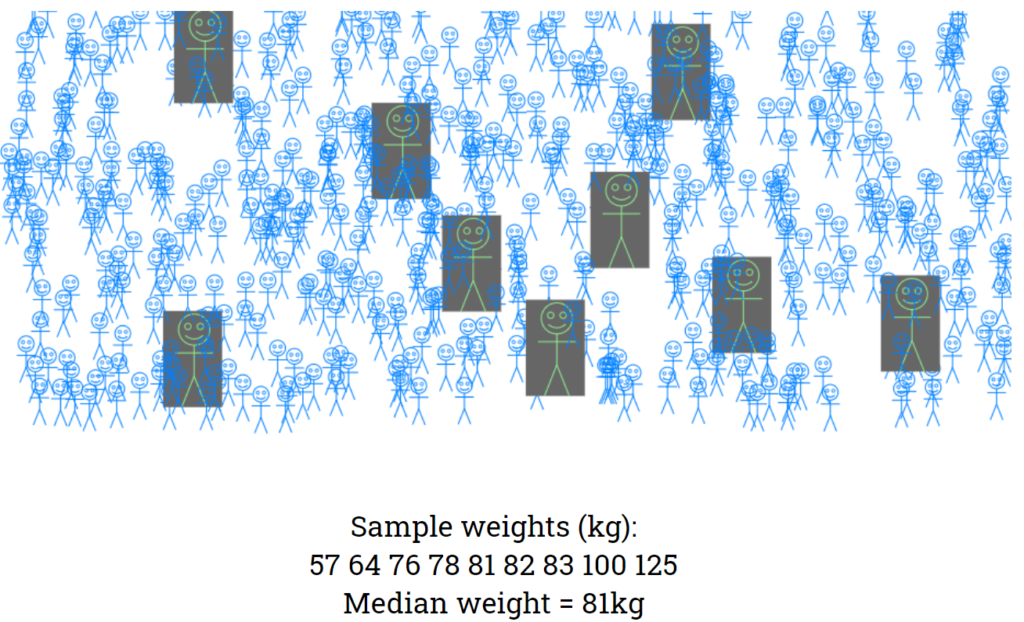
I then ask students to share what their sample median weights are (1) to convince them we all have different samples and (2) for them to “hear” the variability in sample medians. I don’t reveal at this stage what the “true” median weight of all the males is. Instead, the interactive displays a big button that says “How many of you got the population median (the median weight of all males) correct using the sample median as an estimate?”. Clicking the buttons reveals the answer ….

Because I never know how many students will actually be in lectures, I want the interactive to be accessed later for revision, and as you’ll see later, the interactive relies on at least 100 students participating, the 18% is based on a pre-run simulation rather than the “live” samples.
Before we press the next button in the interactive, I ask students what it says on the button “What’s a better way to estimate the median weight of all males?” and hope that they will shout back at me “Use a confidence interval!”. Pressing the next button moves us forward to a screen which shows the student’s point estimate for the median weight from their random sample of males, with a confidence interval with unknown lower and upper limits.

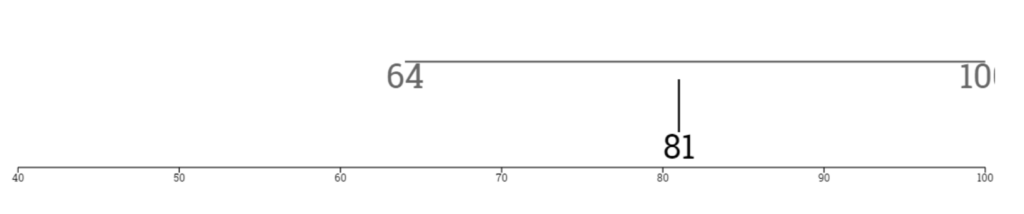
This output of the interactive is “live” (if you scroll back up, 81kg was the median for the random sample in this example). The next part of the interactive is quite “text heavy” but is there because of wanting to provide notes for revision after the lecture.
Again, the numbers used in the example are based on the random sample selected by the student earlier in the interactive. The next part is not based on their random sample, but on the data from the introduction activity.
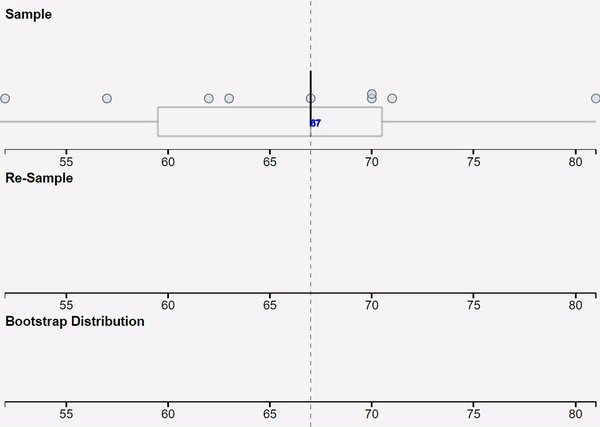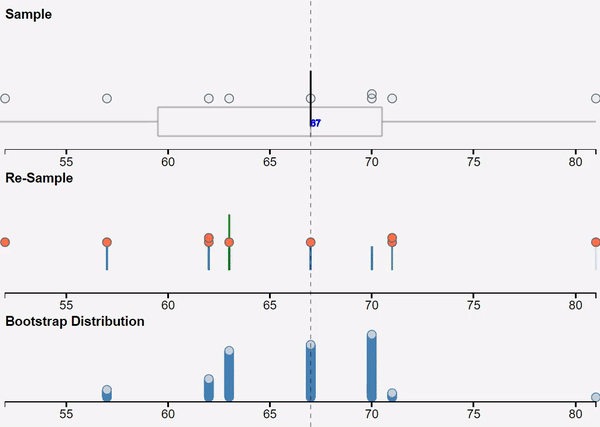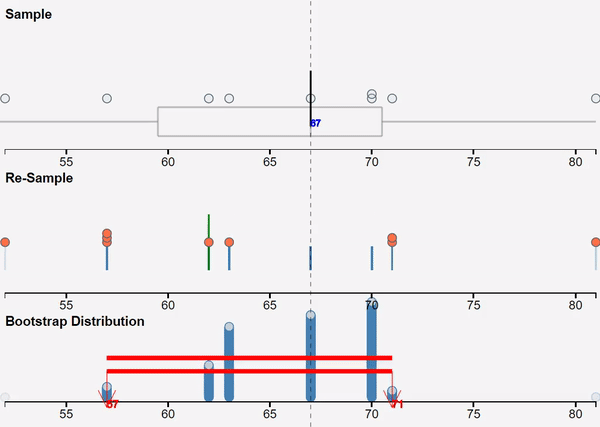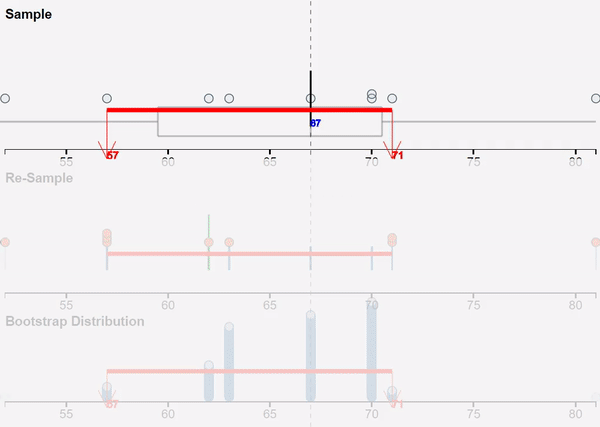
We use VIT online (the web-based version of VIT) for teaching simulation-based inference, and this GIF was used to provide visual reminder of the bootstrapping process. Below the GIF is the next button to move us to the next stage of the interactive, “Get a bootstrap confidence interval using my sample median”, which then displays a bootstrap confidence interval based on the student’s own random sample
In the lecture, I ask some students to share their confidence intervals, so they can hear that we have different lower and upper limits. I also ask them why we have different confidence intervals even though we used the same method. I also ask them if they know if their confidence interval contains the true population median (the median weight of all those male students).
The next button moves us closer to the “finale”, and asks “How many of you got the population median (the median weight of all males) correct using a bootstrap confidence interval from your sample median?” Pressing this button reveals the answer….

As before, the “96%” is fixed and based on a pre-run simulation (but I don’t tell students this!). Again, it’s quite a lot of words but again, revision! The last aspect is totally “teaching world” because of course in reality, we don’t know what the true value of the parameter is but ….. the button says “Show me 100 of our different sample medians and bootstrap confidence intervals” and animates the classic “confidence interval coverage” visualisation we’ve all used….

This last animation also shows that the median weight of all males was 70 kg. Confidence intervals that contain 70 are coloured green, the rest are coloured red. The interactive finishes with the summary below:

You can try out the interactive for yourself here: learning.statistics-is-awesome.org/weights/
Reflecting on the design of the interactive
Overall, I am still happy with the design of the interactive but I hate the data-context! So, in addition to what I discuss below, I want to use a much more interesting and compelling data-context when I find time to re-design this interactive. Maybe something on the level of Jared Wilbur’s alpacas: jwilber.me/permutationtest/
Things I would keep the same:
- The different “screens” of the interactive in terms of chunking up the learning sequence
- The “scroll down” design so each button reveals the next “screen” but the earlier screens stay on the page
- Students selecting their random sample by tapping on a stick person (they think it’s fun!)
- The use of each student’s random sample throughout the interactive
Things I would change/remove:
- Swap the stick people for something else and make the selection process not so clunky
- Change the animation of the bootstrap confidence interval to be based on the student’s random sample
- Make some of the “text heavy” sections not so overwhelming by using “read more” links (so there for revision, but not for reading in the lecture), or by getting students to interact with the text in some way
- Everything to do with the coding!
Things I would introduce:
- Some way to enable students to have to “measure” something from each “thing” sampled (rather than just use weight, which is already measured)
- Some sort of lock feature for the buttons, so I can control when they are able to be pressed rather than relying on 300 students to follow my instructions 🙂
- Options to change how many things are sampled to allow for greater flexibility for the interactive e.g. we could do it again but with a sample size of 40
- Options to change what statistic is used e.g. mean
- More and better animations/graphics
I’m still working on how to design these kinds of lecture-implemented large-scale interactives! Although I hate the context, my students respond really well to the stick people interactive when I use it, and I like how I still get to ask questions and promote students to discuss aspects of their learning with each other as we move through the interactive. I really like the idea that the same interactive could be used in an engaging way in a lecture, but also serve a revision purpose later outside of the lecture.
Anna is a Lecturer in the Department of Statistics, University of Auckland.